Data pipeline to visualize data from an IoT device based on standard services of the Google Cloud Platform

Key prerequisite:
- Data-driven
- Free of charge
- Cloud first, only
After Microsoft Azure and Amazon Web Services (AWS), the Google Cloud Platform (GCP) was the third-most used Public Cloud provider in the year 2021.[1] Just like the other Cloud providers, it offers multiple products as-a-Service (aaS) related to Infrastructure aaS, Platform aaS, or Software aaS (cf. Google Cloud products). There is also the typical Cloud trap of „20+ free products“ as well as of „$300 in free credits“ [2], aiming for a vendor lock-in on client-side. Google even provides a detailed comparison of its own service offerings to the other two big players in the Cloud game: Azure and AWS
The Scope
Based on the variety of Cloud services offered and the Cloud trap of free products, we are implementing a data pipeline for a typical use case in the scope of the Internet of Things (IoT). The cloud-native pipeline should collect and visualize data of an IoT device like the famous ESP32 based on Cloud services. More precisely, the pipeline streams the data from the source to a dashboard, including the processing and storing of the data in the Cloud. As key prerequisite of the cloud-native pipeline related to IoT data, we define the following three measures:
- Data-driven: End-to-end pipeline for data from source to user
- Free of charge: No fees for using the services offered in GCP
- Cloud first, Cloud only: Only Cloud services used, no services on-site
Luckily, we are fulfilling all three as you find out next.
The Pipeline
The following figure shows the different stages of the data pipeline, starting at the source till the visualization of the data. Furthermore, it also highlights the corresponding services used of the Google Cloud Platform in each stage:
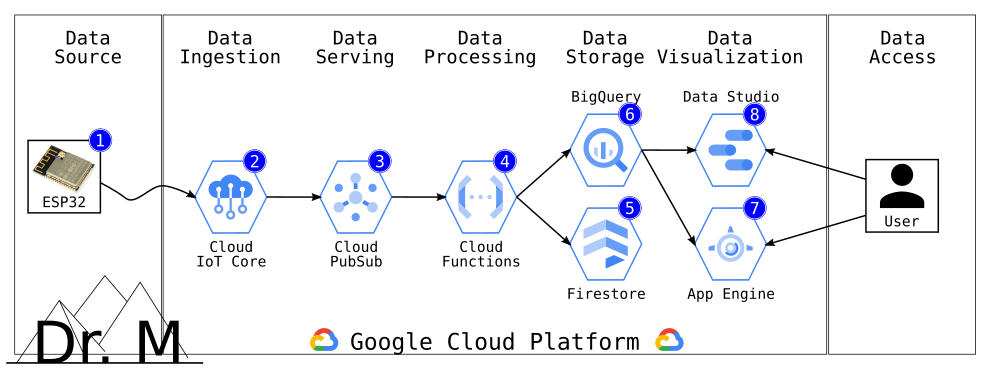
based on Services of the Google Cloud Platform
The overall pipeline includes seven stages, why we split this technical guide into seven posts along the different stages:
- The 1st stage is about the Data Source, focusing on the IoT device like monitoring the environment, structuring the information monitored, and sending the structured information to the Cloud. For more information about the first stage, visit the related blog post.
<Stay tuned, blog and link follow soon> - The 2nd stage is about the Data Ingestion, focusing on the service Cloud IoT Core. It is a message broker — more precisely, an MQTT broker — with additional functionality like a device registry. For more information about the first stage, visit the related blog post.
<Stay tuned, blog and link follow soon> - The 3rd stage is about the Data Serving, focusing on the service Cloud PubSub. It offers to ingest events for streaming into data lakes or databases. For more information about the first stage, visit the related blog post.
<Stay tuned, blog and link follow soon> - The 4th stage is about the Data Processing, focusing on the service Cloud Functions. It offers Serverless Computing, also known as Function as a Service (FaaS), for a variety of programming languages. For more information about the first stage, visit the related blog post.
<Stay tuned, blog and link follow soon> - The 5th stage is about the Data Storage, focusing on the services BigQuery and Firestore. BigQuery offers a serverless, highly scalable, and cost-effective data warehouse. Firestore offers a flexible, fully managed, and scalable NoSQL database (document database). For more information about the first stage, visit the related blog post.
<Stay tuned, blog and link follow soon> - The 6th stage is about the Data Visualization, focusing on the services Data Studio and App Engine. Data Studio offers interactive dashboards and beautiful reports. App Engine offers highly scalable applications on a fully managed serverless platform. For more information about the first stage, visit the related blog post.
<Stay tuned, blog and link follow soon> - Last, the 7th stage is about the Data Access, focusing on the service Identity-aware Proxy (IAP). It offers the usage of identity and context to guard access to Internet-facing applications. For more information about the first stage, visit the related blog post.
<Stay tuned, blog and link follow soon>
The Summary
The Cloud enables the change from CapEx (Capital Expenditures) to OpEx (Operational Expenditure) by shifting investments for the on-premise infrastructure to payments for the usage of managed services at the Cloud. Based on the managed services offered of the Google Cloud Platform (GCP), we build a cloud-native pipeline for data related to an IoT use case. The data pipeline includes seven stages, ranging from the data source like an IoT device to the data access like user identity. Furthermore, we define the following key prerequisite to be fulfilled: Data-driven, free of charge, and Cloud first, only. And, as you can read in the separate blog posts for each stage, we nailed! We build an end-to-end pipeline for IoT data that totally uses managed services in the Cloud — more precisely, the GCP — without any fees charged.
References
- Worldwide Market Share of Service Providers for Cloud Infrastructure from the 4th quarter 2017 to the 3rd quarter 2021 [last checked 2021-11-15]
- Google Cloud Free Programm [last checked 2022-02-09]
Neueste Kommentare